전 편에서 스크래핑으로 얻은 종목데이터를 데이터베이스로 구축해본다.
종목코드 데이터
stocks
# OUTPUT
comp_name code tob main_products listing_date sett_month ceo_name homepage region type
0 JS전선 005560 절연선 및 케이블 제조업 선박선,고무선,전력선,통신선 제조 2007-11-12 12월 이익희 http://www.jscable.co.kr 충청남도 KS
1 거북선2호 101380 NaN 운송장비(선박) 임대 2008-04-25 12월 신주선 NaN 부산광역시 KS
2 거북선6호 114140 NaN NaN 2009-10-01 12월 김연신 NaN 제주특별자치도 KS
3 교보메리츠 064900 NaN 부동산 투자,운용 2002-01-30 12월 김 상 진 NaN 서울특별시 KS
4 국제관광공사 028780 NaN NaN 1966-03-18 12월 NaN NaN NaN KS
... ... ... ... ... ... ... ... ... ... ...
2308 한프 066110 컴퓨터 및 주변장치 제조업 OPC Drum 2002-07-16 12월 유한성 http://www.baiksanopc.co.kr 제주특별자치도 KQ
2309 해성옵틱스 076610 사진장비 및 광학기기 제조업 휴대폰용 렌즈모듈 및 카메라모듈 2013-11-06 12월 이을성, 이재선(각자대표이사) http://www.hso.co.kr 경기도 KQ
2310 행남사 008800 기타 식품 제조업 자기 1993-09-03 12월 김대홍 http://www.haengnam.co.kr 전라남도 KQ
2311 홈센타홀딩스 060560 기타 전문 도매업 건축자재,레미콘 2002-07-11 12월 박 병 윤 http://www.home-center.co.kr 대구광역시 KQ
2312 힘스 238490 특수 목적용 기계 제조업 OLED Mask 인장기, OLED Mask 검사기 등 2017-07-20 12월 김주환 http://www.hims.co.kr 인천광역시 KQ
컬럼 별 Maximum lengh확인
import numpy as np
ms = np.vectorize(len)
col_info = dict(zip(stocks, ms(df.values.astype(str)).max(axis=0)))
print(col_info)
# OUTPUT
{'comp_name': 14,
'code': 6,
'tob': 37,
'main_products': 82,
'listing_date': 10,
'sett_month': 3,
'ceo_name': 42,
'homepage': 48,
'region': 7}각 컬럼별 Maximum length를 참고하여 TABLE을 설계한다.
mariaDB Library 설치
pip install mariadbDATABASE 생성
(Maria db가 설치되어있다는 기준으로 진행한다 - 설치 전 이라면 여기를 참고한다. )
CREATE DATABASE mystock;DB 연결
( root 가 아닌 서비스 이름과 관련 된 user를 생성하여 관리하는 것이 좋다. )
import mariadb
conn = mariadb.connect(user='root', password='****', database='mystock', host='localhost') #1
cursor = conn.cursor() #2
cursor.execute("SHOW DATABASES") #3
rows = cursor.fetchall() #4
print(rows)
# OUTPUT
[('information_schema',),
('myboard',),
('mysql',),
('mystock',),
('performance_schema',),
('test',)]#1: 접속 정보를 넣고 DB에 접속, 커넥션 객체를 얻는다.
#2: 커서 객체를 얻는다. 커서 객체로 쿼리를 실행한다.
#3: 현재 연결된 database(stock)의 모든 테이블을 조회한다.
#4: list 데이터는 fetchall() 함수를 통해 결과데이터를 얻는다. ( 결과는 위와 상이할 수 있다. )
상장법인 마스터 테이블 생성
CREATE_TABLE_COMM_STOCK = """
CREATE TABLE IF NOT EXISTS comm_stock(
code CHAR(6) PRIMARY KEY COMMENT '종목코드',
type CHAR(2) NOT NULL COMMENT '시장구분',
comp_name VARCHAR(50) NOT NULL COMMENT '회사명',
tob VARCHAR(100) COMMENT '업종',
main_products VARCHAR(150) COMMENT '주요제품',
listing_date CHAR(10) COMMENT '상장일',
sett_month VARCHAR(10) COMMENT '결산월',
ceo_name VARCHAR(100) COMMENT '대표자명',
homepage VARCHAR(100) COMMENT '홈페이지',
region VARCHAR(100) COMMENT '지역'
)
"""
cursor.execute(CREATE_TABLE_COMM_STOCK)
MariaDB 설치시 같이 설치 된 HeidisSQL로 접속하여 결과 확인
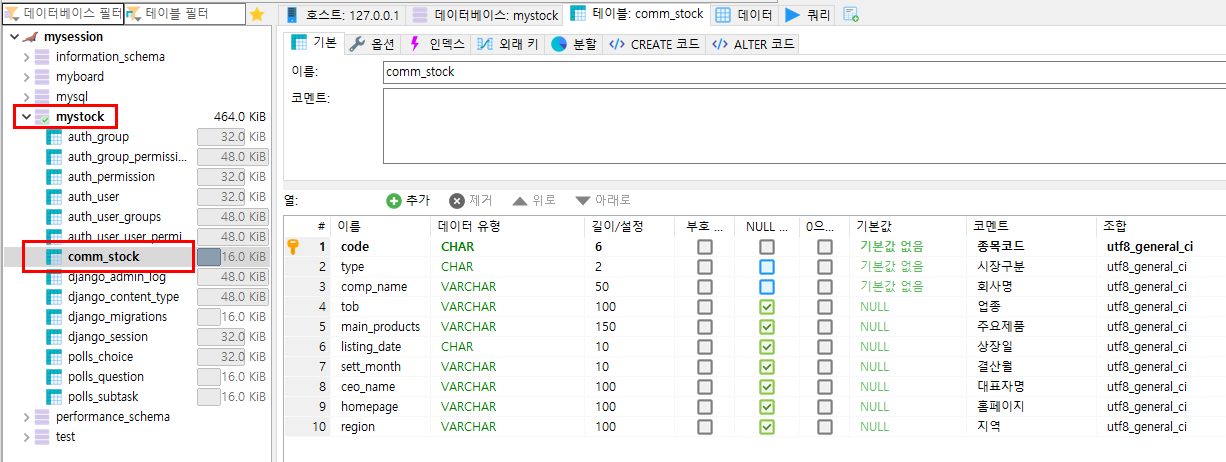
INSERT Query
생성된 comm_stock 테이블에 stocks dataframe 데이터를 넣어보자.
INSERT_TABLE_COMM_STOCK = """
INSERT INTO comm_stock
(
code, type, comp_name,
tob, main_products, listing_date,
sett_month, ceo_name, homepage,
region
)
VALUES
(
?, ?, ?,
?, ?, ?,
?, ?, ?,
?
)
"""실행하기 전에 stocks dataframe을 위 Insert query에 명시된 컬럼 순으로 재정렬한다.
stocks = stocks[['code', 'type', 'comp_name', 'tob', 'main_products', 'listing_date', 'sett_month', 'ceo_name', 'homepage', 'region']]Dataframe을 tuple Array 형태로 변환하여 Insert query의 인자로 넘겨준다.
( Dataframe의 to_sql 함수를 사용해서 간단하게 DML쿼리를 실행할 수 있다. )
data = list(stocks.itertuples(index=False, name=None))
cursor.executemany(INSERT_TABLE_COMM_STOCK, data)
conn.commit()executemany 함수로 n개의 복수데이터를 인자로 넘긴다. 실행 후 commit() 함수 호출하여 트랜잭션에 대해 commit 한다.
HeidisSQL 결과 확인
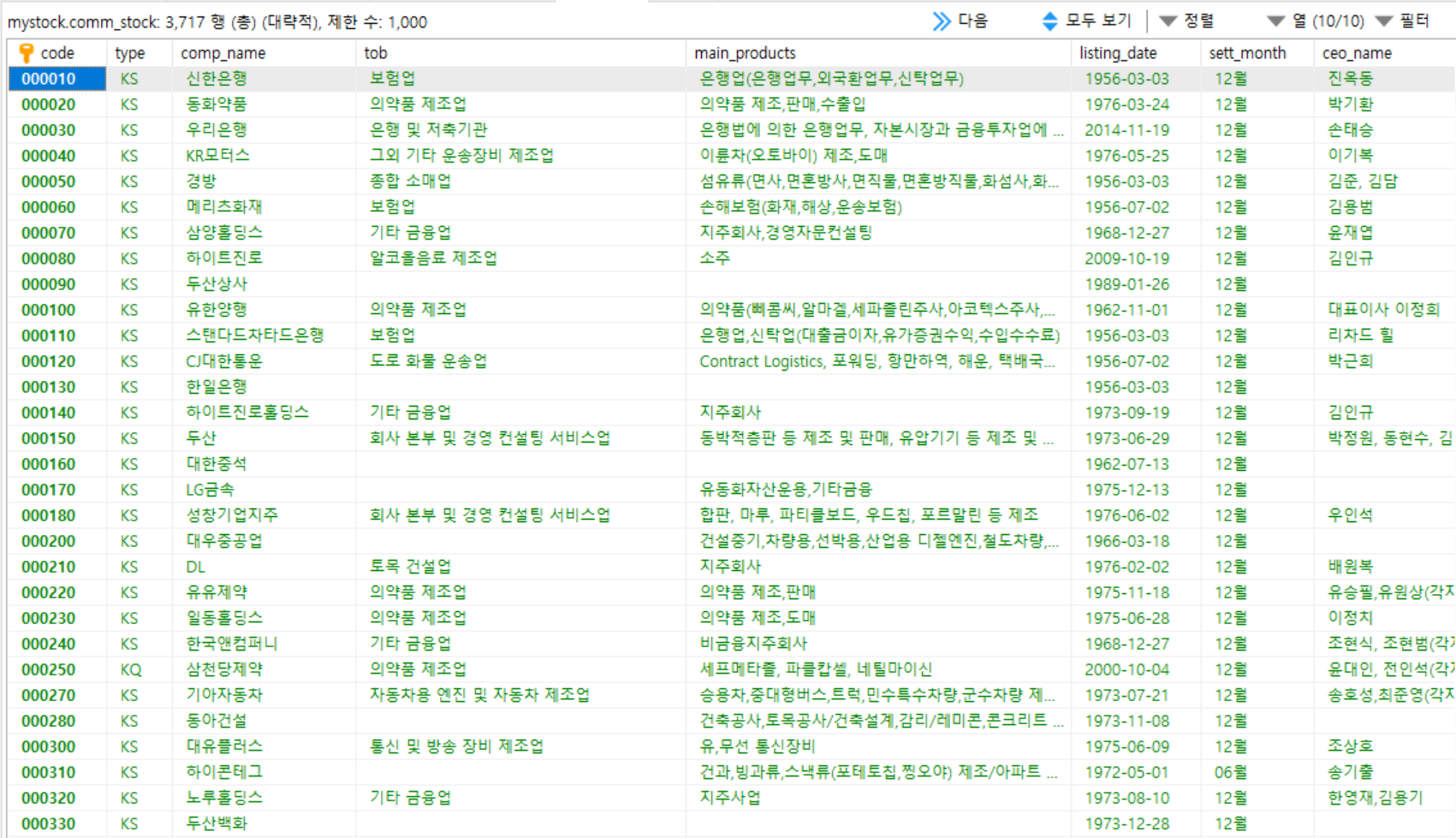
종목코드 마스터 테이블을 설계하고 데이터를 입력했다. 더 나아가서 관계테이블을 생성할 수 있을 것이다. 주식 상세 정보, 주가 정보, 기업 뉴스등 데이터베이스를 확장해보도록 하자.
반응형
'python > 주식' 카테고리의 다른 글
| Python - 상장법인 종목코드 초간단 스크래핑(코스피, 코스닥 구분) (0) | 2021.02.19 |
|---|---|
| Backtrader - ImportError: cannot import name 'warnings' from 'matplotlib.dates' 오류 처리 방법 (0) | 2021.02.17 |
| 1. Python 주식 일간 변동률 계산 - ( 삼성전자 vs 애플 시각화 비교 ) (2) | 2021.02.16 |
| 3. Python - Plotly 캔들차트 + 이동평균선 ( feat. rolling API 사용법 ) (4) | 2021.01.27 |
| 2. Python - Plotly 캔들 + 거래량 차트 만들기 ( 복수 차트 생성 ) (1) | 2021.01.26 |